This article is about programming C/C++ language with Arduino Nano, Arduino Uno, LGT8F328P [NANO F328P-C] and ET-BASE AVR EASY32U4 (Figure 1) or other boards and platforms using C language for learning to code another type of data structure management program that has different storage and management methods, called BST or Binary Search Tree, as in Figure 2, which is a structure that can be applied to collecting data with attributes in which the data on the left node is less than current node and the right node is greater than current node or the opposite, the left node is greater and the right noe is less. Thus, searching for data in the event that the tree is balanced both left and right on the BST structure saves time or number of searches per round by half of available data, for example, there are 100 data sets in the first round, if the current node is not what you’re looking for it, the choice left is to find from the left or right node. This selection causes the data of the other side to be ignored or cut it in half approximately but if the Binary Search Tree is unbalanced, the search speed will not be much different from the Sequential Search.

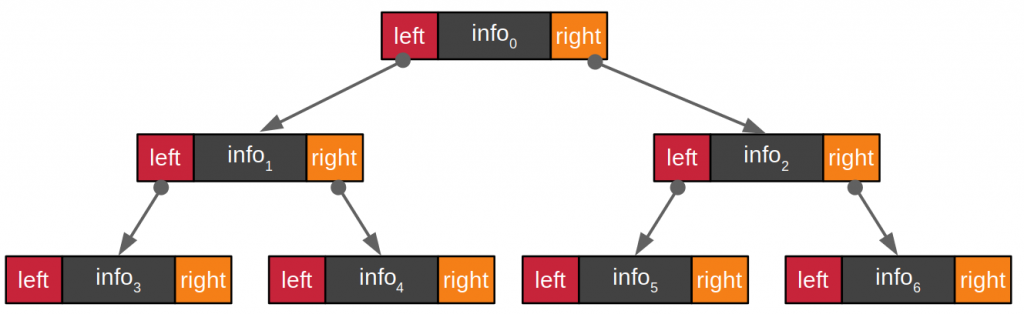
BST structure
BST data structure is a collection of data that has 3 structures as shown in Figure 2 and 3. In the first figure, the data stored in the tree structure consists of nodes, and this node consists of 3 parts:
- left for storing the position of the node that is on the left side of the current node.
- info for storing the current node’s data
- right for storing the position of the node on the right side

Node of BST
From Figure 2, it can be written as a BSTNode class to store data of BST nodes as follows:
struct node {
node * left;
int info;
node * right;
};In the code above you will find that we created 3 variables or properties of the node, namely
- left for storing the node position on the left. The default value is NULL.
- info for storing data values defined during tree construction.
- right for storing the position or pointing to the right node. The default value is NULL.
Node appending
Adding a node to BST can be done in 3 cases:
- The added data already exists.
- The added data is less than the current node.
- The added data is greater than the current node.
If the data already exists, it will be reported as duplicate data (or don’t report to increase the performance).
The command set for creating a new node is as follows.
node* newNode(int info) { // Create new node
node* new_node = (node*)malloc(sizeof(node));
if (new_node != NULL) {
new_node->left = NULL;
new_node->right = NULL;
new_node->info = info;
}
return new_node;
}Code for insert()
node * insert(node * pNode, int info) {
if (pNode == NULL) {
Serial.print("Insert ");
Serial.print(info);
Serial.println("... done.");
return newNode(info);
}
if (pNode->info < info) {
pNode->left = insert( pNode->left, info);
} else if (pNode->info > info) {
pNode->right = insert(pNode->right, info );
} else if (pNode->info == info){
Serial.println("This information is a duplicate of what already exists.");
}
return pNode;
}Traversing
There are three ways to search or traverse into the BST to access the data of each node:
Pre-order Traversing
The pre-order type has the working principle of making a VLR as follows:
- Retrieve the data (V)
- If you can go left, go left. (L)
- If not, go right. (R)
Code for pre-order traversing
void preorder( node *root) {
if (root != NULL) {
preorder(root->left);
preorder(root->right);
Serial.println(root->info);
}
}In-order Traversing
The working principle of in-order traversing is different from LVR which is as follows.
- If you can go left, go left. (L)
- Retrive the data (V)
- If you can go right, go right. (R)
The code for in-order traversing can be written as follows.
void inorder( node *root) {
if (root != NULL) {
inorder(root->left);
Serial.println(root->info);
inorder(root->right);
}
}Post-order Traversering
In the case of port-order type, it works as LRV:
- If you can go left, go left. (L)
- If you can go right, go right. (R)
- Retrieve the data (V)
From the procedure, you can see that the post-order code is
void postorder( node *root) {
if (root != NULL) {
Serial.println(root->info);
postorder(root->left);
postorder(root->right);
}
}Code
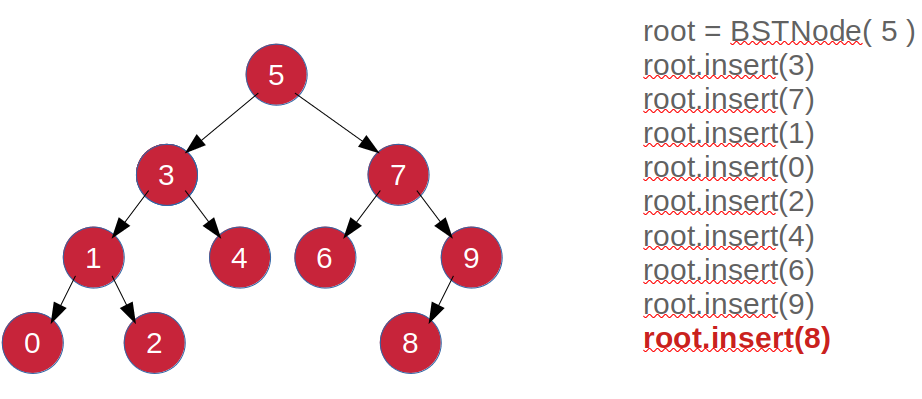
Example program for adding nodes with 5, 3, 7, 1, 0, 2, 4, 6, 9 and 8, which when done by hand, will result as Figure 4.
struct node {
node* left;
int info;
node* right;
};
node* newNode(int info) { // Create new node
node* new_node = (node*)malloc(sizeof(node));
if (new_node != NULL) {
new_node->left = NULL;
new_node->right = NULL;
new_node->info = info;
}
return new_node;
}
void inorder( node *root) {
if (root != NULL) {
inorder(root->left);
Serial.println(root->info);
inorder(root->right);
}
}
void preorder( node *root) {
if (root != NULL) {
preorder(root->left);
preorder(root->right);
Serial.println(root->info);
}
}
void postorder( node *root) {
if (root != NULL) {
Serial.println(root->info);
postorder(root->left);
postorder(root->right);
}
}
node * insert(node * pNode, int info) {
if (pNode == NULL) {
Serial.print("Insert ");
Serial.print(info);
Serial.println("... done.");
return newNode(info);
}
if (pNode->info < info) {
pNode->left = insert( pNode->left, info);
} else if (pNode->info > info) {
pNode->right = insert(pNode->right, info );
} else if (pNode->info == info){
Serial.println("This information is a duplicate of what already exists.");
}
return pNode;
}
node * rootNode = NULL;
void setup() {
Serial.begin(9600);
rootNode = insert( rootNode, 5);
rootNode = insert( rootNode, 3);
rootNode = insert( rootNode, 7);
rootNode = insert( rootNode, 1);
rootNode = insert( rootNode, 0);
rootNode = insert( rootNode, 2);
rootNode = insert( rootNode, 4);
rootNode = insert( rootNode, 6);
rootNode = insert( rootNode, 9);
rootNode = insert( rootNode, 8);
Serial.println("---------- Pre-order -----------");
preorder(rootNode);
Serial.println("---------- In-order -----------");
inorder(rootNode);
Serial.println("---------- Post-order -----------");
postorder(rootNode);
}
void loop() {
}
Result
Insert 5... done.
Insert 3... done.
Insert 7... done.
Insert 1... done.
Insert 0... done.
Insert 2... done.
Insert 4... done.
Insert 6... done.
Insert 9... done.
Insert 8... done.
---------- Pre-order -----------
8
9
6
7
4
2
0
1
3
5
---------- In-order -----------
9
8
7
6
5
4
3
2
1
0
---------- Post-order -----------
5
7
9
8
6
3
4
1
2
0Note: The order of the show must be viewed from bottom to top.
Conclusion
From this article, it will be found that understanding the working principles of data structures can be applied to the C language, and if understanding the method of selecting commands will enable those codes to be used on a variety of platforms. As an example in this article, we test it on PCs that are Linux and macOS or various microcontrollers such as Arduino Nano, Arduino Uno, LGT8F328P [NANO F328P-C] and ET-BASE AVR EASY32U4
ข้อดีของ BST ยังคงเป็นกรณีที่เมื่อต้นไม้มีความสมดุลย์จะทำให้การค้นหานั้นรวดเร็วกว่าการค้นหาแบบลำดับมาก ๆ แต่ถ้าเมื่อใดที่ต้นไม้ไม่มีความสมดุลย์ และเสียสมดุลย์ไปทางข้างใดข้างหนึ่งมาก ๆ เช่น ถ้าเพิ่มข้อมูลเป็น 1,2,3,4,5,6,7,8,9 และ 10 จะพบว่าต้นไม้ทั้งหมดเอียงขวา คือ มีแต่โหนดทางขวา เมื่อทำการค้นหาจึงทำงานเหมือนเป็นการหาแบบลำดับ แต่เพิ่มเวลาของการทำงานที่เป็นส่วนของการตรวจสอบโหนดทางซ้าย โหนดทางขวาและการย้ายโหนดเข้าไปจะทำให้ความเร็วของการทำงานนั้นย่ำแย่กว่าการใช้แถวลำดับหรือ Array กับการเก็บข้อมูล 1 ถึง 10 และค้นหาแบบเรียงลำดับ
The advantage of BST is still the case that when the tree is balanced the search is much faster than sequential search. But when the tree is out of balance and very unbalanced to one side for example, if adding data as 1,2,3,4,5,6,7,8,9 and 10 will find that all trees are right skewed i.e. only right nodes. When searching, it works like a sequential search. But it increases the time of the work that is part of checking the left and right nodes and traversing nodes in will cause the speed of execution to be much worse than using an array with 1 to 10 data collection and sequential search.
Finally, enjoy programming.
(C) 2020-2023, By Jarut Busarathid and Danai Jedsadathitikul
Updated 2023-02-03